Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Середина интервала, |
Расчетные значения |
||||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки: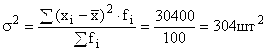
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 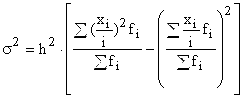
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту;  – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Определение групповой, средней из групповой, межгрупповой и общей дисперсии
Пример 2. Нахождение дисперсии и коэффициента вариации в группировочной таблице
Пример 3. Нахождение дисперсии в дискретном ряду
Пример 4. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию
Построим интервальную группировку. Определим размах интервала по формуле:
![]()
где X max– максимальное значение группировочного признака;
X min–минимальное значение группировочного признака;
n – количество интервалов:
Принимаем n=5. Шаг равен: h = (192 - 159)/ 5 = 6,6
Составим интервальную группировку

Для дальнейших расчетов построим вспомогательную таблицу:

X"i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:

Определим дисперсию по формуле:
Формулу можно преобразовать так:

Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии , вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i - величина интервала;
А - условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
m1 - квадрат момента первого порядка;
m2 - момент второго порядка
Дисперсия альтернативного признака (если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
Внутригрупповая дисперсия характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi - групповая средняя;
ni - число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Дисперсия в статистике определяется как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. Распространенный способ расчета квадратов отклонений вариантов от средней с их последующим усреднением.
![]()
В экономически-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения, оно представляет собой корень квадратный из дисперсии.
 (3)
(3)
Характеризует абсолютную колеблемость значений варьирующего признака выражается в тех же единицах измерения, что и варианты. В статистике часто возникает необходимость сравнения вариации различных признаков. Для таких сравнений используется относительный показатель вариации, коэффициент вариации.
Свойства дисперсии:
1)если из всех вариант вычесть какое-либо число, то дисперсия от этого не изменится;
2) если все значения вариант разделить на какое-либо число b, то дисперсия уменьшится в b^2 раз, т.е.
3) если исчислить средний квадрат отклонений от какого-либо числа с неравного средней арифметической, то он будет больше дисперсии . При этом на вполне определенную величину на квадрат разности между средней величиной поc.
![]()
Дисперсию можно определить как разницу между средним квадратом и средней в квадрате.
17. Групповая и межгрупповая вариации. Правило сложения дисперсии
Если статистическая совокупность разбита на группы или части по изучаемому признаку, то для такой совокупности могут быть исчислены следующие виды дисперсии: групповые (частные), средне групповые (частных), и межгрупповая.
Общая
дисперсия
–
отражает вариацию признака за счет всех
условий и причин, действующих в данной
статистической совокупности.
![]()
Групповая дисперсия - равна среднему квадрату отклонений отдельных значений признака внутри группы от средней арифметической этой группы, называемой групповой средней. При этом групповая средняя не совпадает с общей средней для всей совокупности.
![]()
Групповая дисперсия отражает вариацию признака только за счет условий и причин, действующих внутри группы.
Средняя групповых дисперсий - определяется как среднее взвешенное арифметическое из дисперсий групповых, причем весами являются объемы групп.
Межгрупповая дисперсия - равна среднему квадрату отклонений групповых средних от общей средней.
Межгрупповая дисперсия характеризует вариацию результативного признака за счет группировочного признака.
Между рассмотренными видами дисперсий существует определенное соотношение: общая дисперсия равна сумме средней групповой и межгрупповой дисперсии.
Это соотношение называется правилом сложения дисперсии.
18. Динамический ряд и его составные элементы. Виды динамических рядов.
Ряд в статистике - это цифровые данные, показывающие, изменение явления во времени или в пространстве и дающие возможность производить статистическое сравнение явлений как в процессе их развития во времени, так и по различным формам и видам процессов. Благодаря этому можно обнаружить взаимную зависимость явлений.
Процесс развития движения социальных явлений во времени в статистике принято называть динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя (например, число осуждённых за 10 лет), расположенных в хронологическом порядке. Их составными элементами являются цифровые значения данного показателя и периоды или моменты времени, к которым они относятся.
Важнейшая характеристика рядов динамики - их размер (объём, величина) того или иного явления, достигнутых в определённых период или к определённому моменту. Соответственно, величина членов ряда динамики - его уровень. Различают начальный, средний и конечный уровни динамического ряда. Начальный уровень показывает величину первого, конечный - величину последнего члена ряда. Средний уровень представляет собой среднюю хронологическую вариационного рада и исчисляется в зависимости от того, является ли динамический ряд интервальным или моментным.
Ещё одна важная характеристика динамического ряда - время, прошедшее от начального до конечного наблюдения, или число таких наблюдений.
Существуют различные виды рядов динамики, их можно классифицировать по следующим признакам.
1) В зависимости от способа выражения уровней ряды динамики подразделяются на ряды абсолютных и производных показателей (относительных и средних величин).
2) В зависимости от того, как выражают уровни ряда состояние явления на определённые моменты времени (на начало месяца, квартала, года и т.п.) или его величину за определённые интервалы времени (например, за сутки, месяц, год и т.п.), различают соответственно моментные и интервальные ряды динамики. Моментные ряды в аналитической работе правоохранительных органов используются сравнительно редко.
В теории статистики выделяют рады динамики и по ряду других классификационных признаков: в зависимости от расстояния между уровнями - с равностоящими уровнями и неравностоящими уровнями во времени; в зависимости от наличия основной тенденции изучаемого процесса - стационарные и не стационарные. При анализе динамических рядов исходят из следующего уровни ряда представляют в виде составляющих:
Y t = TP + Е (t)
где ТР – детерминированная составляющая определяющая общую тенденцию изменения во времени или тренд.
Е (t) – случайная компонента, вызывающая колеблимость уровней.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г . Синтаксис этого выражения имеет следующий вид:
ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.


Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.


Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.